|
Reconstructing a 3D hand from a single-view RGB image is challenging due to various hand configurations and depth ambiguity.
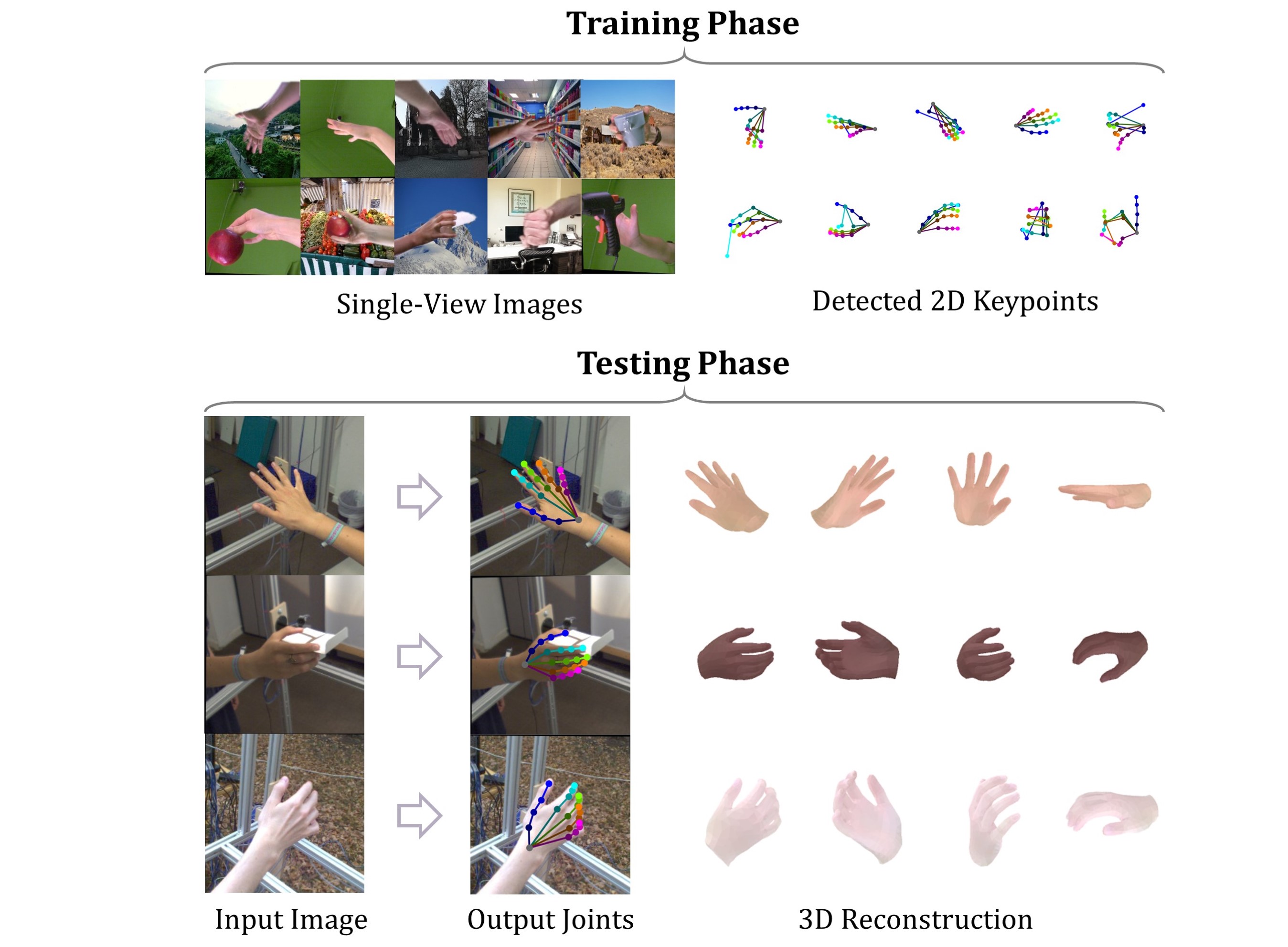
To reliably reconstruct a 3D hand from a monocular image, most state-of-the-art methods heavily rely on 3D annotations at the training stage, but obtaining 3D annotations is expensive.
To alleviate reliance on labeled training data, we propose S2HAND, a self-supervised 3D hand reconstruction network that can jointly estimate pose, shape, texture, and the camera viewpoint.
Specifically, we obtain geometric cues from the input image through easily accessible 2D detected keypoints.
To learn an accurate hand reconstruction model from these noisy geometric cues, we utilize the consistency between 2D and 3D representations and propose a set of novel losses to rationalize outputs of the neural network.
For the first time, we demonstrate the feasibility of training an accurate 3D hand reconstruction network without relying on manual annotations.
Our experiments show that the proposed self-supervised method achieves comparable performance with recent fully-supervised methods.
|